Truth, Lies and BCDR: Global Deduplication
The business continuity and disaster recovery (BCDR) landscape is incredibly dynamic. Advancements in technology transform how we deliver and consume data, and organizations must adapt with agility to protect workloads spread across on-premises infrastructure, remote endpoints, cloud and SaaS applications. As vendors drive change in the space, how do you cut through the marketing noise and separate fact from fiction?
With a myriad of technologies, it is challenging to find the right choice for your business. In our Truth, Lies and BCDR series, we break down a variety of BCDR-related technology topics to help you determine the best fit to meet your organization’s current and future needs.
This week, we look at global deduplication.
What is deduplication?
Data deduplication is the process of eliminating excessive (redundant) copies of data to decrease storage capacity requirements. By looking for similar byte patterns in files or data blocks, deduplication identifies redundancies across directories, data types, servers and locations. The process of deduplication may be run as an inline process (applied as data is being written into the storage system), as a background process (eliminating duplicates after data is written to disk), or as a combination of the two.
When applying deduplication, data is divided into several “chunks.” The way chunks are divided may vary depending on the type of deduplication technique used (e.g., block-level vs. file-level). Each chunk is assigned a unique hash code. New chunks are examined against previous chunks, and if the hash code of one matches the hash code of another, it is deemed a duplicate copy and eliminated.
Given that the same byte pattern may occur hundreds or even thousands of times across an environment (consider the number of times you make small changes to a Word or PowerPoint file), the volume of duplicate data may be significant. Ideally, deduplication ensures only one unique copy of data is stored on the local storage, although in some situations, two copies of each unique block may be retained to balance performance and retention. Subsequent redundant copies of data (files or blocks) are linked to the unique data copy using a “marker” or “pointer.”
Classifying deduplication techniques
The real-world benefits of deduplication technologies depend on a variety of factors including:
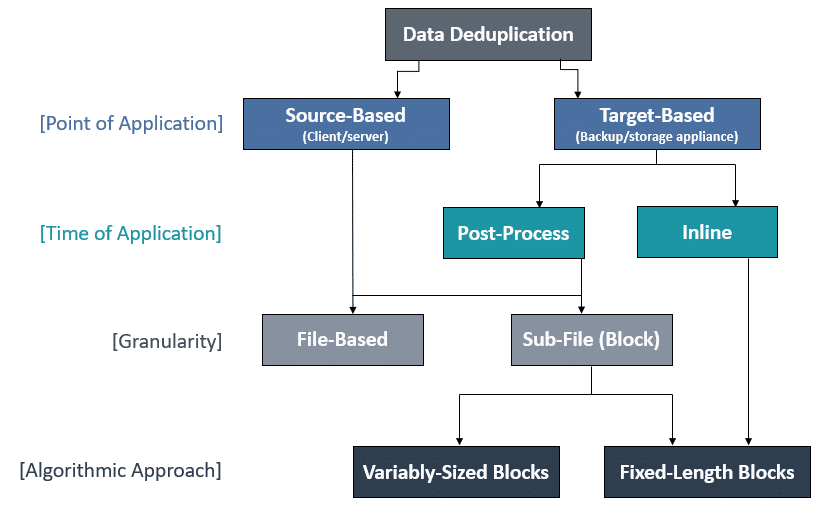
Point of application: where deduplication is applied — source-based vs. target-based.
Time of application: when deduplication is applied — inline vs. post-process.
Granularity: at what level deduplication is applied — file-level vs. sub-file (block) level.
Algorithmic approach: fixed-length blocks vs. variably sized blocks.
A simple explanation of how these factors relate is illustrated in the diagram below:
There are pros and cons to each approach, many of which we have explored in an earlier blog post in greater detail. One aspect of deduplication not addressed above is the concept of global versus custodial (job-based) deduplication, which can have a dramatic impact on your overall storage efficiency.
Global vs. custodial (job-based) deduplication
Deduplication is one of the critical storage technologies organizations rely on to optimize storage efficiency and reduce infrastructure costs. While it is a space-saving feature found in many enterprise storage and backup solutions, a lack of standards makes measuring the effectiveness of data reduction ratios and cost savings difficult when comparing deduplication approaches across different vendors.
Global deduplication
Global deduplication is an incredibly effective process for data reduction, increasing the deduplication ratio to reduce the capacity required to store data. When global deduplication is applied to an inline deduplication technique, a piece of data is written upon ingest and the write is immediately acknowledged by the Single Instance Storage (SIS) directory. Incoming blocks are compared against the SIS in order to identify duplicates in the incoming data set and the implementation is able to identify data that has already been written and will not write it again. When using post-process deduplication, processing occurs as a passive background operation and moves blocks that exist across more than one backup into SIS and eliminates redundancies.
Custodial (job-based) deduplication
Custodial, also known as job-based or per-job deduplication, removes redundant data within a “custodian” or “job.” This is a method seen with HOS (hypervisor) level backups, where a job may refer to a single virtual machine (VM) or a group of similar VMs grouped into a single backup job, with the idea that many VMs may have similar data blocks (e.g., VMs created from the same template).
The fundamental weakness of the per-job approach is that it does not deduplicate across backup jobs. This creates challenges while scheduling and managing backups since the probability of having duplicate data on clones or VMs with the same operating system is relatively high. Job-based deduplication also struggles to scale; new VMs created within the environment over time may not be able to be coupled into existing jobs without impacting performance and backup windows. This means per-job deduplication misses a lot of duplicate data unless you are able to put all VMs into a single backup. Additionally, its performance may degrade over time since it has increased difficulties finding duplicate data in earlier backup jobs.
Unitrends Adaptive Deduplication
Storage-based deduplication in the context of backups is a bit of a paradox. The intent is to increase the amount of local storage available for backups, but all technologies have unintended consequences. In the case of backup deduplication, some of these include:
- Increased backup windows due to decreases in ingest performance (backups get slower because deduplication takes time).
- Increased risk of recovery failure because of a storage failure, rendering a backup or backup chain unrecoverable.
- Decreased performance for archiving to media, such as a disk or tape, since data typically must be “reduplicated” before archiving is performed.
While these concerns can be addressed to some degree technically, the toughest issue transcends the technical challenges of deduplication and gets at the business challenge, substituting processor and memory cycles in place of adding storage. This is the toughest issue because to do so in a manner that benefits the end user, you must ensure the overall price per terabyte of effective storage (the amount of storage after whatever data reduction technique in use is considered) is best for the customer.
Unitrends has taken a different route for the deduplication we utilize in our physical backup appliances and virtual appliances — we call it “Adaptive Deduplication.” Adaptive Deduplication merges advanced compression with global deduplication and utilizes predictive algorithms that take into account processor/memory capabilities and the amount of available storage to automatically apply the optimal data reduction technology on a per-record basis across all backups ingested by the system. Unitrends uses an SHA-512 hash cryptographic function to ensure the integrity of each chunk of data backed up.
Adaptive Deduplication is one of the reasons the concept of a purpose-built backup appliance (integrated all-in-one backup server, hosting dedicated compute, memory, storage and backup software utilities) is gaining traction over the functionally partitioned backup server, backup software and third-party deduplication device that are used across most of the industries today.
By integrating the backup architecture with deduplication, your appliance simply handles decisions with regards to the backup strategy based on temporal data change in the most efficient way possible, rather than forcing those decisions on the user.
Want to learn more? Get in touch today!